

Did you ever think about how do organizations accumulate large high-quality datasets for their business analysis, visualization, and decision-making? Or how do they store massive amounts of data efficiently for future use? If yes then you are in the right place. The answer to these questions is surrounded by Data Engineering and its ecosystem.
In this article, we'll be discussing data and the journey involved with it. Let's get started.
What is Data Engineering?
The field of Data Engineering concerns with the flow and access of data effectively from one system to another. Its goal is to make quality data available for fact-finding and data-driven decision-making.
A huge amount of data is continuously being generated by people, machines, and applications. This data plays an essential role in the growth of the organization by deriving valuable insights. Almost 90% of data is in an unstructured format. Some data sources like IoT devices, machine logs generate a real-time stream of data. Hence it becomes challenging tasks for organizations to extract, process, and store data efficiently.
Data engineering deals with these challenges by evolving with new and better technologies for handling data.
Let's understand the generic flow of data in a particular organization. It may vary from company to company depending on their requirements.
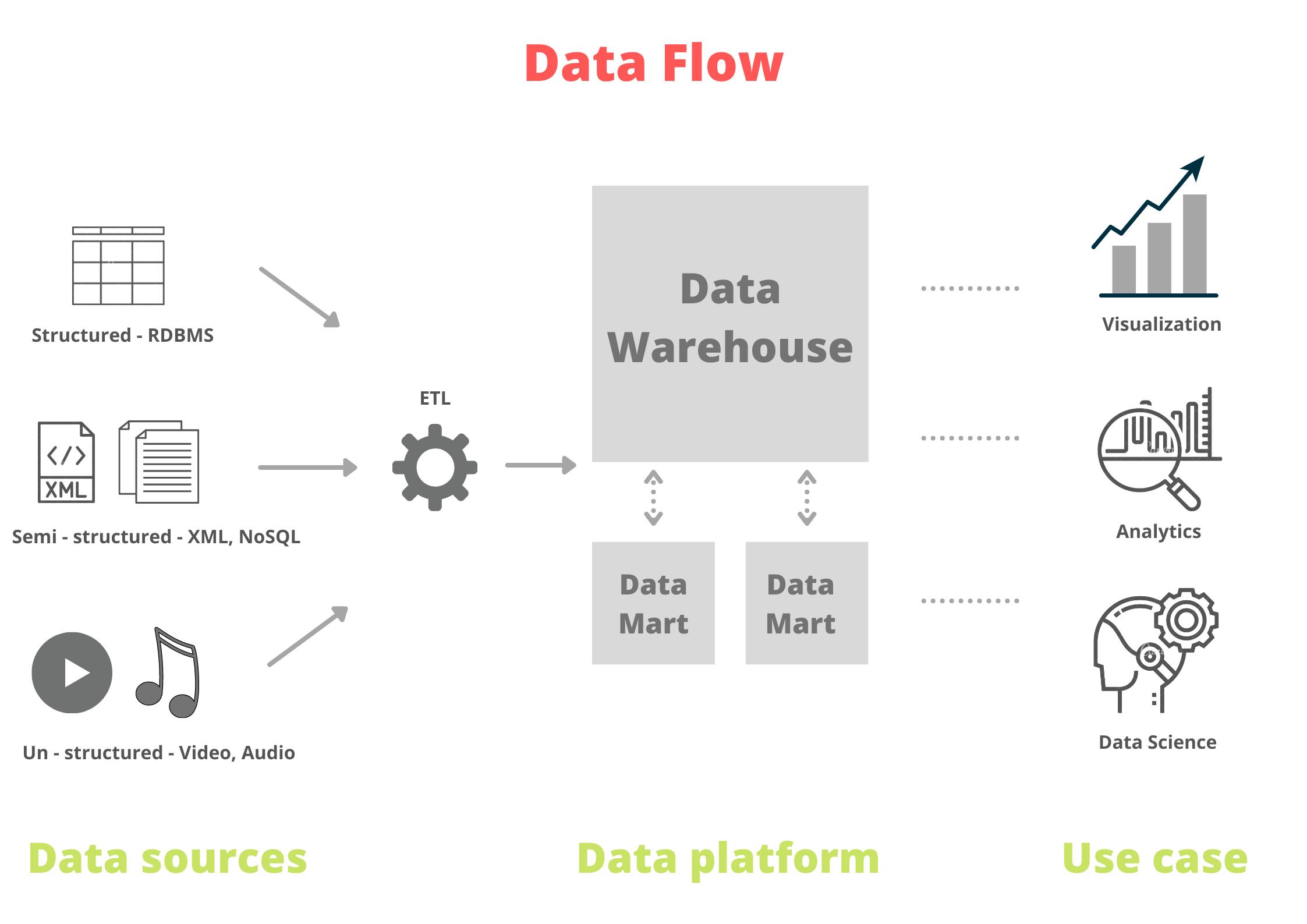
Data Engineering involves
Collecting source data : - Extracting, integrating, and organizing data from disparate sources. Data from Relational or Transactional Databases such as MySQL, Oracle, PostgreSQL, etc. Semi-structured data such as XML files, emails, and popular NoSQL databases like MongoDB, Cassandra. Even unstructured data such as audio, images, files. There are different sets of tools for extracting and managing this diverse data.
Processing data : - It involves cleaning, transforming & preparing data for accurate use cases. Distributed storage & computing by Hadoop is used for large-scale data. Data pipelines are created to maintain the flow of data. Extract-Transform-Load (ETL) and ELT techniques are used.
Storing data : - Highly scalable stores like Data Warehouse, Data Lakes, and Big data platforms are used to store data efficiently. Data storage architecture is the most important decision for the organization as the entire process is highly dependent on storage. Security, backup, and recovery need to be considered while choosing data storage.
Using data : - Several tools such as APIs, services, and programs are designed to retrieve data. Visualization tools are used by business users for data-driven decisions. Data scientists / ML Engineers use this data for developing predictive models.
Now you should be wondering what about its ecosystem. Let us understand the vast ecosystem with the Data Platform Architecture.
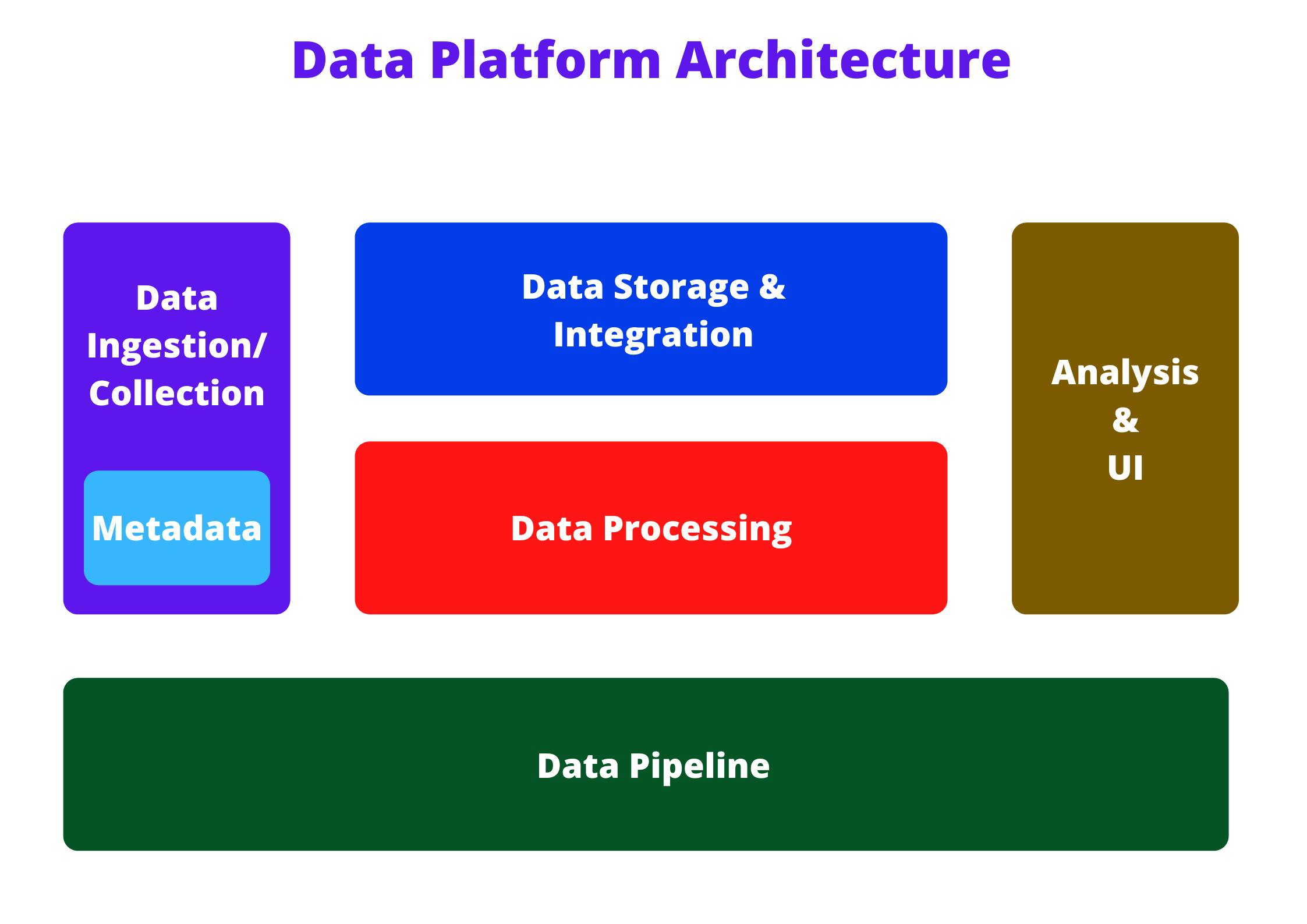
Data Platform Architecture is a multi-layer platform architecture where each layer represents a functional component of the data flow and the coordination among them.
Let's understand each layer
Data Ingestion / Collection layer : -
- This layer is all about the collection/extraction of data from disparate sources.
- It consists of various tools used to collect and aboard data into the platform.
- Incoming data can be either in batch mode or stream mode.
- It also maintains information on the data collected in a metadata repository.
Tools in this layer are: -
IBM Streams
Google DataFlow
Amazon Kinesis
Apache Kafka
Data Storage and Integration : -
- Highly scalable data storage facility for long-term use.
- Transforming or merging data either physically or logically.
- Make data available for processing in batch/stream mode.
- Integration involves practices and techniques to ingest, transform and combine data from several sources.
Tools for Storage: -
IBM DB2, MS SQL Server, Oracle DB, PostgreSQL, Amazon RDS, Azure SQL Database
Cassandra, MongoDB, Redis, neo4j, Azure Cosmos DB
Tools for Integration : -
Talend
Informatica
IBM Infosphere
Data Processing : -
- It involves reading data and applying the required transformation.
- Cleaning data into a standardized format.
- Supports powerful querying tools for analytics.
- Some of the processing tasks are structuring, normalization, denormalization, and cleaning.
Tools : -
Google DataPrep
OpenRefine
Watson Studio Refinery
Data Pipeline : -
- It involves the automated movement of data to and from systems in batch/stream mode.
- Responsible for maintaining continuous data flow in the organization
Tools : -
Apache Airflow
Apache Beam
Google DataFlow
Analysis and UI : -
- Responsible for delivering understandable data to consumers like Business Analysts or Stakeholders.
- Supports querying tools and programming languages to retrieve data.
- Dashboarding and Business Intelligence tools.
Tools : -
Power BI
Jupyter Notebook
A short briefing on few terminologies :
Data Repositories : - It is a general term for data storage containers. Can be broadly categorized into two, Online Transaction Processing (OLTP) for storing a huge volume of operational data. And Online Analytical Processing (OLAP) for storing a huge volume of analytical data. Examples : - Data Warehouse, Data Marts, and Data Lakes.
ETL : - It is a process of extracting, transforming, and loading data into the store. Sometimes transforming is done after loading data, it is called the ELT process.
Bonus Tip :
If you are interested in Data engineering and want to make a career out of it, then here are some topics you should learn and master.
Operating Systems - Unix, Windows, Administration & Automation
Infrastructure Components - Virtual Machines, Networking, Cloud Services
Programming - SQL, Python, Java, Scala
Data Storage - RDBMS (MySQL,Oracle) , NoSQL (MongoDB, CosmosDB, Cassandra) , and Data Warehouses ( Snowflake, Amazon Redshift, Azure Synapse)
Big Data - Hadoop, Spark, and Hive
Data Pipelines - Apache Beam, Apache Kafka
Data Integration - Talend, Informatica